BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=tensor([[[ 4.4496e-01, 4.8276e-01, 2.7797e-01, ..., -5.4032e-02,
3.9394e-01, -9.4770e-02],
[ 2.4943e-01, -4.4093e-01, 8.1772e-01, ..., -3.1917e-01,
2.2992e-01, -4.1172e-02],
[ 1.3668e-01, 2.2518e-01, 1.4502e-01, ..., -4.6915e-02,
2.8224e-01, 7.5566e-02],
[ 1.1789e+00, 1.6738e-01, -1.8187e-01, ..., 2.4671e-01,
1.0441e+00, -6.1970e-03]],
[[ 3.6436e-01, 3.2464e-02, 2.0258e-01, ..., 6.0111e-02,
3.2451e-01, -2.0995e-02],
[ 7.1866e-01, -4.8725e-01, 5.1740e-01, ..., -4.4012e-01,
1.4553e-01, -3.7545e-02],
[ 3.3223e-01, -2.3271e-01, 9.4877e-02, ..., -2.5268e-01,
3.2172e-01, 8.1079e-04],
[ 1.2523e+00, 3.5754e-01, -5.1320e-02, ..., -3.7840e-01,
1.0526e+00, -5.6255e-01]],
[[ 2.4042e-01, 1.4718e-01, 1.2110e-01, ..., 7.6062e-02,
3.3564e-01, 2.8262e-01],
[ 6.5701e-01, -3.2787e-01, 2.4968e-01, ..., -2.5920e-01,
2.0175e-01, 3.3275e-01],
[ 2.0160e-01, 1.5783e-01, 9.8974e-03, ..., -3.8850e-01,
4.1308e-01, 3.9732e-01],
[ 1.0175e+00, 6.4387e-01, -7.8147e-01, ..., -4.2109e-01,
1.0925e+00, -4.8456e-02]]], grad_fn=<NativeLayerNormBackward0>), pooler_output=tensor([[-0.6856, 0.5262, 1.0000, ..., 1.0000, -0.6112, 0.9971],
[-0.6055, 0.4997, 0.9998, ..., 0.9999, -0.6753, 0.9769],
[-0.7702, 0.5447, 0.9999, ..., 1.0000, -0.4655, 0.9894]],
grad_fn=<TanhBackward0>), hidden_states=None, past_key_values=None, attentions=None, cross_attentions=None)
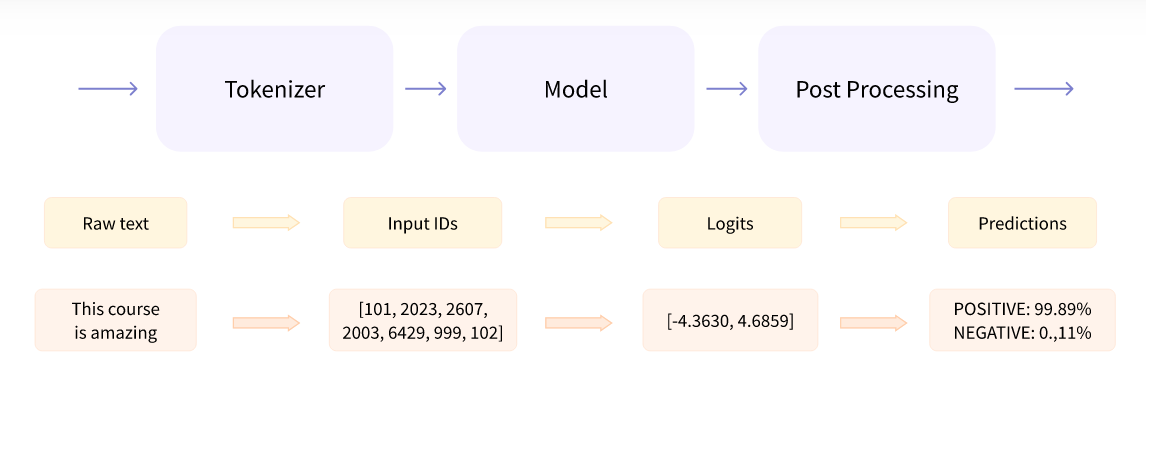
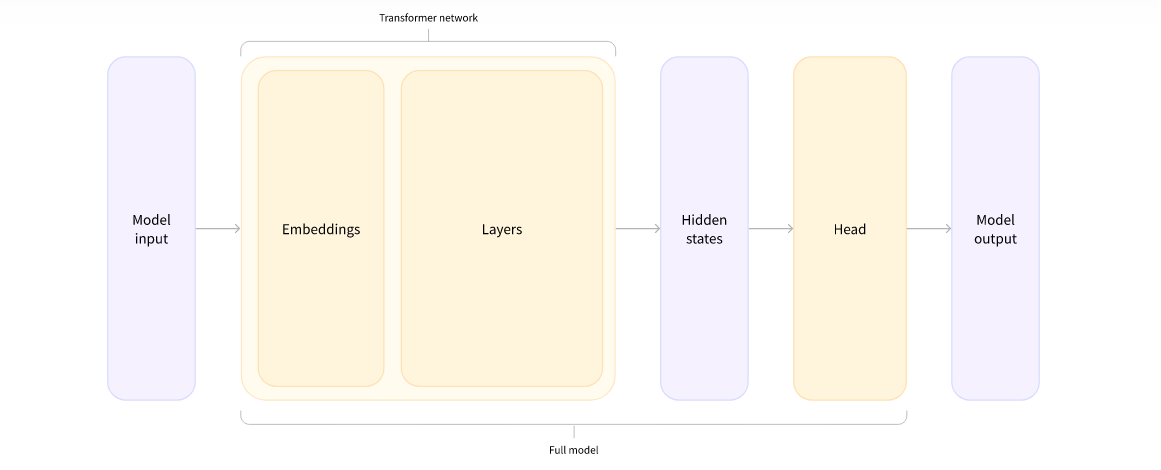
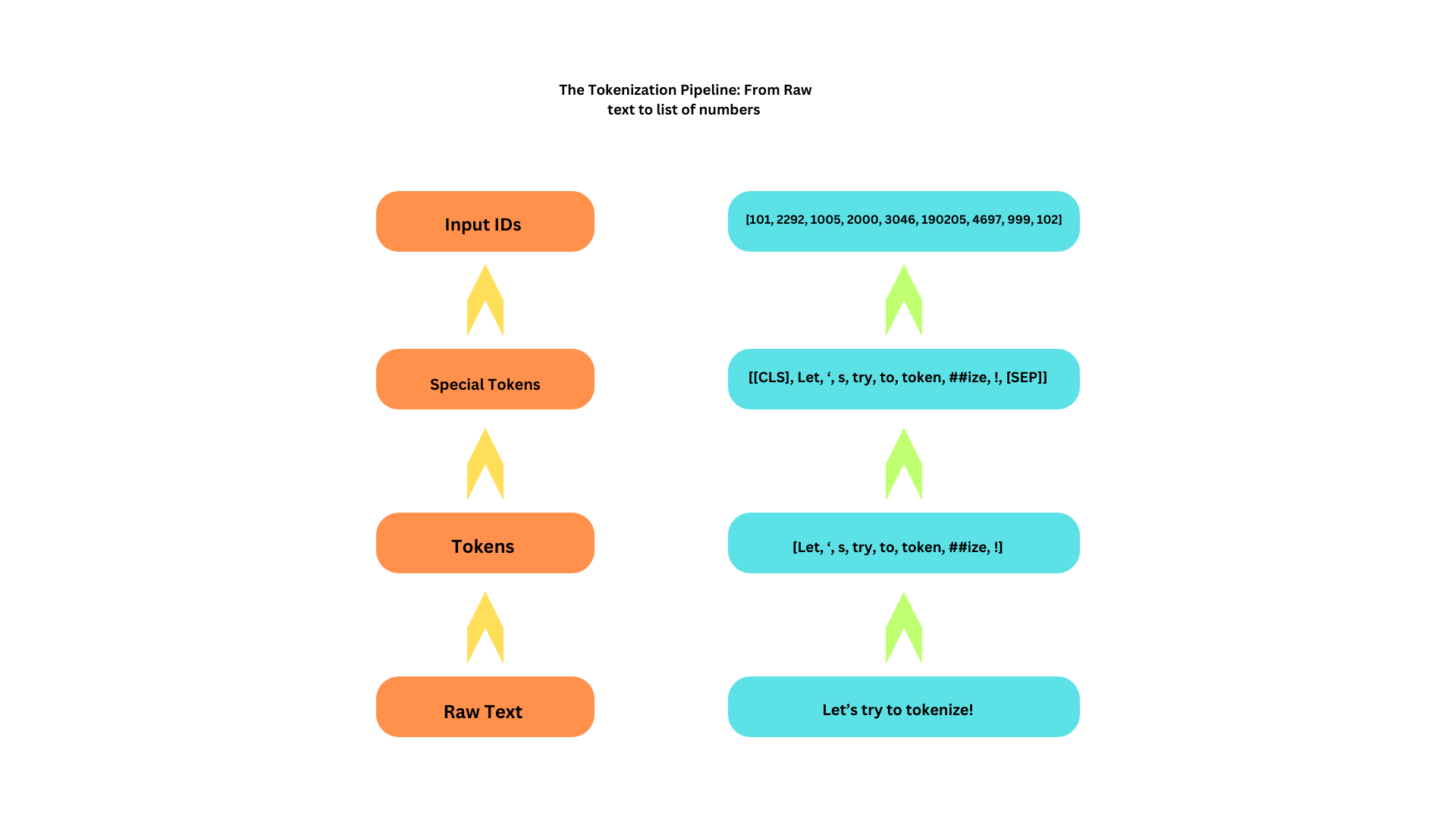 * The first we create token-word, ,ostly complete words, but in some cases the one word will be splited to 2 or more parts. - this sub parts can be dentified by the
* The first we create token-word, ,ostly complete words, but in some cases the one word will be splited to 2 or more parts. - this sub parts can be dentified by the