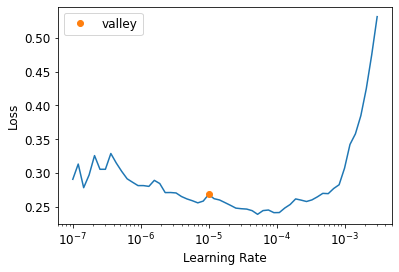
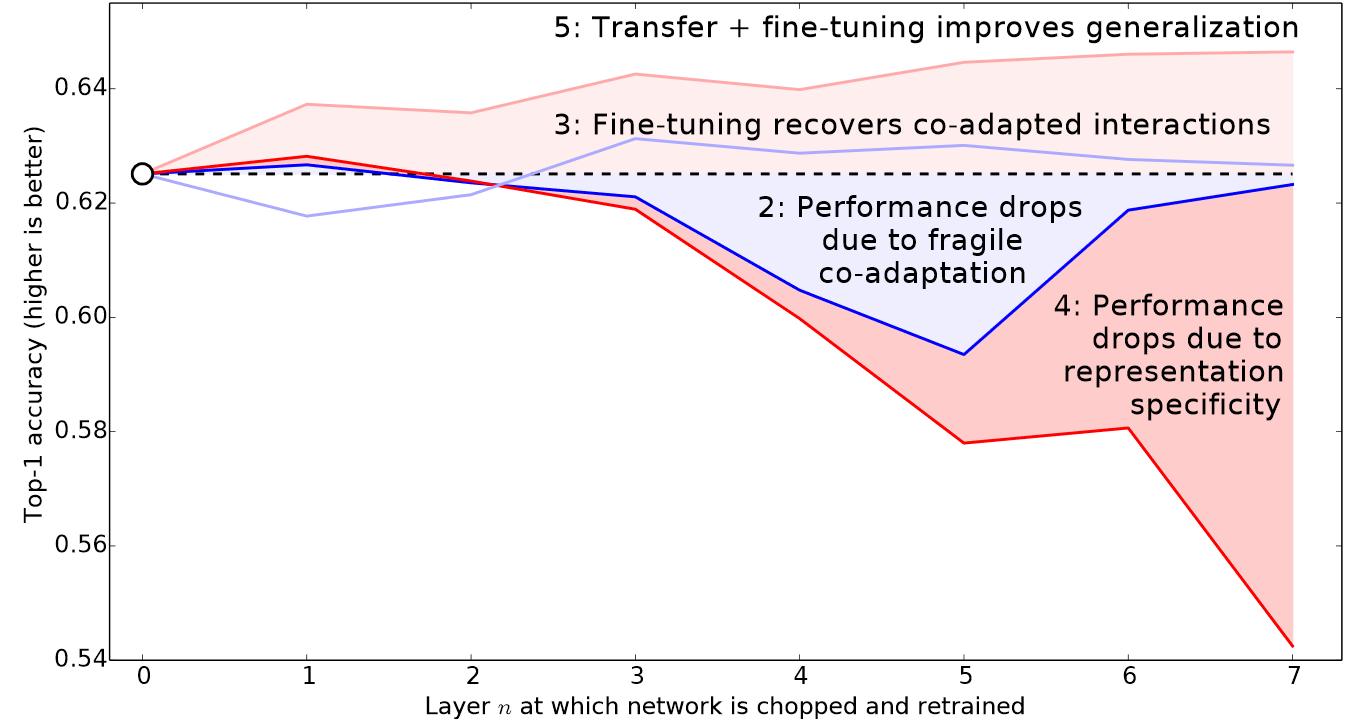
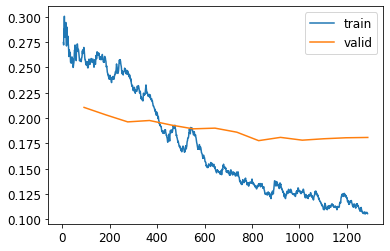
! [ -e /content ] && pip install -Uqq fastbook
import fastbook
fastbook.setup_book() |████████████████████████████████| 719 kB 30.4 MB/s
|████████████████████████████████| 1.3 MB 60.3 MB/s
|████████████████████████████████| 5.3 MB 53.0 MB/s
|████████████████████████████████| 441 kB 66.2 MB/s
|████████████████████████████████| 1.6 MB 54.6 MB/s
|████████████████████████████████| 115 kB 75.5 MB/s
|████████████████████████████████| 163 kB 67.3 MB/s
|████████████████████████████████| 212 kB 71.5 MB/s
|████████████████████████████████| 127 kB 76.1 MB/s
|████████████████████████████████| 115 kB 62.1 MB/s
|████████████████████████████████| 7.6 MB 58.8 MB/s
Mounted at /content/gdrive